Previously, we discuss the basic programming model of CUDA: memory and thread. In this note, we will dive into the hardware implementation. By doing this, we can better understand the philosophy of CUDA programming, so as to accelerate the computation.
The GPU architecture is built around a scalable array of multi-threaded Streaming Multiprocessors (SMs). There are usually numerous SMs in every GPU. And every SM can host hundreds of threads. When a CUDA program on the host GPU invokes a kernel grid, the blocks of the grid are enumerated and distributed to multiprocessors with available and distributed to SMs with available execution capacity.
Note that the block can only be executed on the SM assigned. The threads of a thread block execute concurrently on one SM and multiple thread blocks can execute concurrently on one SM.
To manage such a large number of threads, it employs a unique architecture called SIMT (Single Instruction, Multiple Threads). We will elaborate on it.
SIMT
SM creates, manage, schedule and execute threads in groups of 32 parallel threads (warps, 中文:线程束). Individual threads composing a wrap start together at the same program address, but they have their own instruction address counter and register state(This is the fundamental difference). They are free to branch and execute independently.
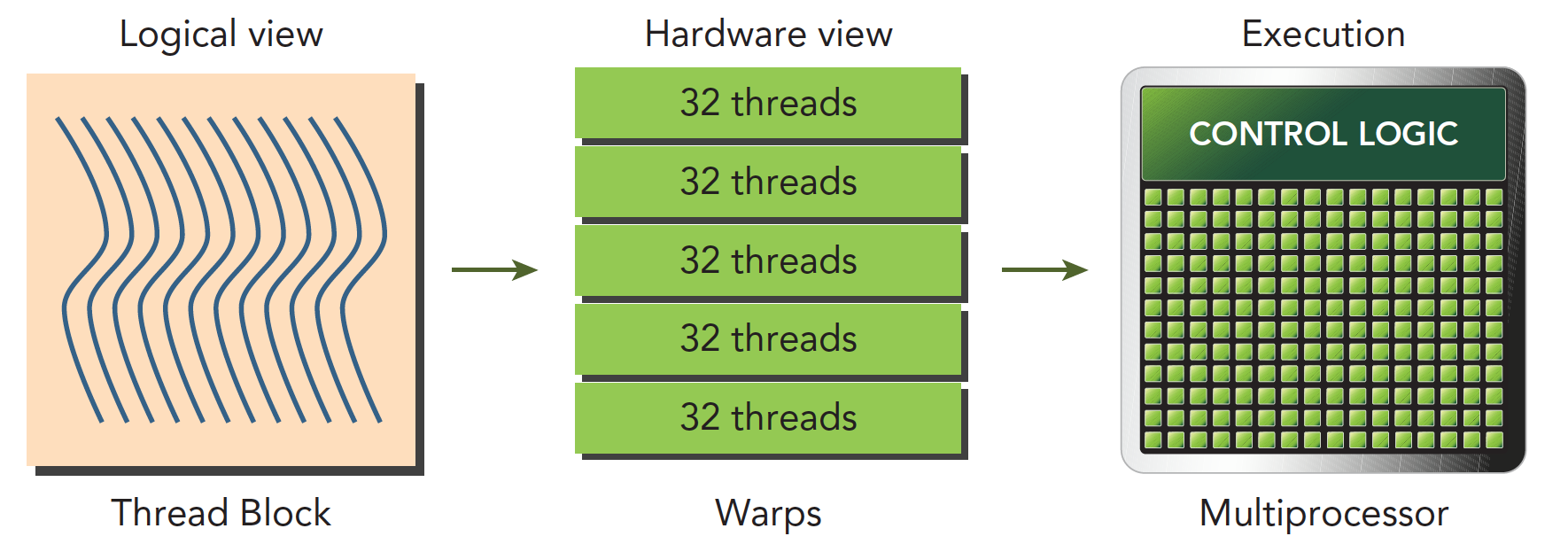
When a SM is given one or more thread blocks to execute, it partitions them into warps and each warp gets scheduled by a warp scheduler for execution. The way a block is partitioned into warps is always the same. Each warp contains threads of consecutive, increasing thread IDs with the first warp containing thread 0. We have talked about how to index the thread previously.
A warp executes one common instruction at a time, so full efficiency is realized when all 32 threads of a warp agree on their execution path. (Important)
Managing the divergence is the key to performance. If the threads in a warp diverge with control flow (e.g. if-else), the warp serially executes each path taken by some threads, masking out threads that are not on that path. For example,
if (con)
{
//do something I
}
else
{
//do something II
}
When a warp executes this code, it is likely that 16 threads do something I while the other 16 run something II.